今天使用 MS SQL Server 2005,要設定資料庫的定期備份,開啟「維護計畫」,出現了以下訊息:

此時下達以下 SQL 指令將 Agent XPs 元件開啟即可:
參考資料
今天使用 MS SQL Server 2005,要設定資料庫的定期備份,開啟「維護計畫」,出現了以下訊息:
此時下達以下 SQL 指令將 Agent XPs 元件開啟即可:
參考資料
上一個部份提到 COMMIT 與 ROLLBACK,有一點需要注意的地方,就是 CREATE TABLE、ALTER TABLE、DROP TABLE …. 等語法,是隱含著 COMMIT 指令的,因此是無法被 ROOLBACK 的喔!
資料型態
Oracle 提供的資料型態很多,僅針對比較常用的來筆記。
VARCHAR2
這是處理字元資料最有效率的資料型態,長度範圍介於 1~4000;另外比較需要注意的是 NVARCHAR2,是用來儲存 Unicode 的字元。
CLOB (Character Large Object)
儲存超大型的字元資料,最大可以到 (4 -1) GB * database block size。
NUMBER
除了用來儲存整數外,浮點數也可以!
BINARY_FLOAT & BINARY_DOUBLE
比 NUMBER 更進階的浮點數型態,精準度更高,計算速度更快,儲存所需的空間也較少。
DATE
日期型態,支援許多不同的顯示格式。
TIMESTAMP
常用來追蹤事件發生的順序之用。
資料表(Table)
create table
alter table
管理 table index (索引)
當 table 中有 primary key 時,其實 Oracle 就會自動將 primary key 的欄位建立索引了!
create index
modify index
更詳細的 index 管理的語法,可以參考官方網站的文件:
檢視表(View)
以下是從 WIKI 上找來關於 View 的的資料:
===== 開始 =====
檢視表 (View) 是在關聯式資料庫中,將一組查詢指令構成的結果集組合成可查詢的資料表的一種資料庫物件。與資料表不同的是,資料表是一種實體結構(Physical Structure),但檢視表是一種虛擬結構(Virtual Structure),在實體資料表中的改變都可以立刻反應在檢視表中,不過部份資料庫管理系統也支援具更新能力的檢視表(Updatable View)。
檢視表具有下列的好處:
===== 結束 =====
VIEW 的建立
VIEW 的修改
VIEW 的更名
刪除 VIEW
Sequence
Sequence 就像 MS SQL Server 中的流水號一樣,是 Oracle 用來管理流水號的資料庫物件,目的是用來產生循序且唯一的值
Sequence 的值如何使用? 主要是要透過兩個虛擬欄位,分別為:
需要注意的是,在 MS SQL Server 中,流水號是依附在特定 table 的特定欄位上;但在 Oracle 中,sequence 跟任何的 database object 都沒有關係。
因此若要拿 sequence 來產生流水號給 table 當 primary key,在 sequence 在命名時可以加入 table 名稱作為方便辨識之用。
建立 SEQUENCE
刪除 SEQUENCE
參考資料
Synonym
synonym 其實就是 schema object 的別名,除了可以用來協助簡化 SQL 語法外,還可以協助隱藏真正的 database object(基於某些安全考量)。
假設當 database 名稱被修改時,可以透過 synonym 的方式來避免應用程式的修改。
建立 SYNONYM
移除 SYNONYM
更詳細的資料,可以參考官方網站的文件:
參考資料
何謂 DMZ ? 可以看看以下兩篇文章:
DMZ 最大的目的就是要將公開提供服務的主機與內部網段隔離,即使公開主機被入侵或是中毒,也不會影響到內部網路。
在 Untangle 中,要進行 DMZ 的設定,必須在 Network 選項中開啟 Advanced Mode,並進入 Interface 中進行設定。
在 DMZ 的設定中,有三種不同的 Config Type,分別為 static、dynamic、bridge,分別說明如下:
static
若是 public IP 數量不足,沒有辦法讓 DMZ 中的主機各自擁有 public IP 的話,那就必須要設定為 private IP。
若要處理 external –> DMZ 的網路流量,由於 untangle 對外僅有 external 介面,因此必須透過 port forwarding 的方式來進行設定。(若 public IP 足夠也可以用 IP alias 的方式來作)
再來就是 DMZ –> external 這一段,這裡需要設定 NAT policy,最簡單的設定方式為:
| Address and Netmask | Source Address |
| 0.0.0.0 / 0 | auto |
這樣設定代表網路封包怎麼過來,就怎麼回去,Untangle 在中間並沒有做什麼額外的篩選動作。
其中 Address & Netmask 的部份,是設定在 DMZ 中需要將網路封包進行 NAT 動作的主機;Source Address 則是只要 NAT 到哪個 external interface,因此這邊設定的是 external interface 的 IP address。(如果只有一個 external interface,直接設定 auto 即可)
因此若是在 DMZ 中有台主機 IP 為 192.168.1.1/24,特別指定要 NAT 到 IP 為 61.61.61.61 的 IP,可以使用以下設定:
| Address and Netmask | Source Address |
| 192.168.1.1 / 24 | 61.61.61.61 |
最後 firewall 的部份就必須要針對要開放的服務進行設定,可透過 Packet Filter 或是 Firewall service 進行設定。
dynamic
還搞不清楚這要如何設定……有空再來補…
bridge
以下是官方網站對 bridge 選項的說明:
If selected, bridges any two interfaces. A common use is when you want to bridge the Untangle Server's DMZ interface to the Untangle Server's external interface. It's not uncommon for the DMZ to have an internal IP address; in fact, the main reason you might want to bridge the DMZ to the External is so that you don't need to assign the DMZ its own external IP addresses.
若是在 DMZ 中的 server 都各自擁有自己的 public ip(也就是跟 Untangle server 的 external interface 擁有同網段的 IP address),而管理者也希望可以讓外面的連線直接透過 server 的 ip 進行連線,就可以設定為 bridge mode,以下是其他設定:
設定完後,只要 firewall 的部份設定無誤(External 與 Internal 的 source 與 port;若是沒有設定,就是直接讓網路封包通過),就可以通啦!
基本上,針對需要開放的對外服務來設定防火牆的規則,不要全部開放,才是比較安全的作法。
參考資料
在鳥哥的網站上看到的: 
另外在國外網站上偶然看到的,覺得蠻一目了然的,因此留下來
(資料來源:Quick HOWTO : Ch14 : Linux Firewalls Using iptables - Linux Home Networking) 
另外還有一張更清楚的……不過很大就是了!
鼎鼎有名的 Untangle 應該不用詳加說明了吧?
它是一套 open source 且功能很強大的 UTM(Unified Threat Management),對於預算不夠卻想要建置 UTM 的單位,是很合適的選擇。
另外,如果想瞭解 VPN 是什麼,以及 OpenVPN 的相關概念,可以參考之前的幾篇文章:
要設定 Untangle 中的 OpenVPN,有幾個步驟是必須要完成的:
設定 OpenVPN 類型
在 Untangle 的 OpenVPN 設定中,可以將其設定為:
【備註】若是有需求,Untangle 也可以同時設定為 VPN server 與 client 喔!
Generate Certificate
由於在 vpn tunnel 的資料傳輸需要加密,而加密需要金鑰,金鑰的驗證需要靠 CA。
因此在這個步驟中必須輸入相關資訊以產生 CA 的憑證。(此時 Untangle 扮演一台 Self-Signed CA,並自行產生憑證)
Add Address Pools
address pool 的設定就是要設定 VPN server(這裡指的是 Untangle) 配發給 vpn client 的 private IP address 範圍。 
Add Exports
這個部份則是設定 VPN server(這裡指的是 Untangle) 要開放給外部 VPN client 可以連線的內部網段;要注意的是,這邊設定的不是 address pool 中設定的網段,而是內部實際的網段喔!
透過 IP address 與 Netmask 的設定,可以決定開放存取的範圍;基本上為了安全性考量,盡量還是僅開放確定要提供給 vpn client 存取的網段即可。 
Add VPN Clients
在這個步驟中,要設定可以連線到 VPN server 的 client。
剛開始設定時,僅能設定 client name 並指定其屬於哪個 address pool。因為 address pool 可能不只一個,而多個 client 的話可能會分別屬於不同的 address pool。
若是有針對不同使用者群組來分成不同網段的話,就可以透過將 client 指定給不同的 address pool 的方式來達成。 
Add VPN Sites
此功能是用於與其他的 VPN server 對連時的設定,目前還尚未用到,因此先略過,之後再來補充…
金鑰檔的傳輸
金鑰檔傳輸的方面,Untangle 可以用 E-Mail 或是 USB 的方式;但 E-Mail 只會給下載連結,但如果 Untangle Server 沒有 Public IP 以及 Domain Name 的話,根本就連不到,這時候可能就需要 USB 了!
但如果都不行呢? 那就只好進去終端機了…(預設 ssh 是沒開的,但可以到本機把服務打開!)
使用者的金鑰檔都存在「/usr/share/untangle/conf/openvpn/client-packages」資料夾中,檔名為「config-xxxx.zip」,其中 xxxx 為使用者名稱;知道檔案位置以後,就可以透過 scp 傳到自己的主機上囉! 
連線至 OpenVPN server
取得金鑰檔之後,就可以透過 OpenVPN client 軟體連線至 VPN server 囉! 以 OpenVPN GUI 為例,要將金鑰檔案放到「C:\Program Files\OpenVPN\config」目錄中,連線時不需要輸入帳號密碼,連線後可從 VPN server 中取得一組虛擬 IP,並可透過 VPN tunnel 連線至內部主機。
問題處理
在設定完 OpenVPN 之後,卻發生了連上 OpenVPN server 後,無法連進 Internal Network 的問題,經過以下檢查:
到底是為何呢? 當初也是百思不得其解;後來另外找台 NB 來測試,卻發現通了! 後來在原來的 client 上 run 一個 virtual machine,簡單裝個 Windows 2003,也通了!
我想原因應該是公司在電腦上安裝了會影響 OpenVPN 封包的軟體吧!
在 Untangle 的論壇上也有人有同樣情形,不過他是更換網路卡就好了!
所以可能會發生這樣情況的原因似乎不少,但設定照上面說明的就沒錯了!
參考資料
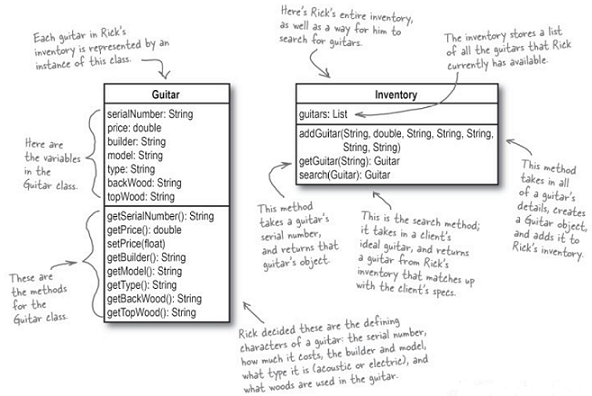
原本的設計
為了增加曼陀林(Mandolin,一種與 Guitar 性質差不多的樂器)的支援,於是將 Mandolin 與 Guitar 的共用特性抽取出來,變成以下的設計
然而,既然 Guitar 有 GuitarSepc,當然 Mandolin 也要有自己的 MandolinSpec 囉!
現在有了 GuitarSpec 與 MandolinSpec,下一個步驟要做的就是將兩者的共同特性給抽取出來成為一個獨立的 class
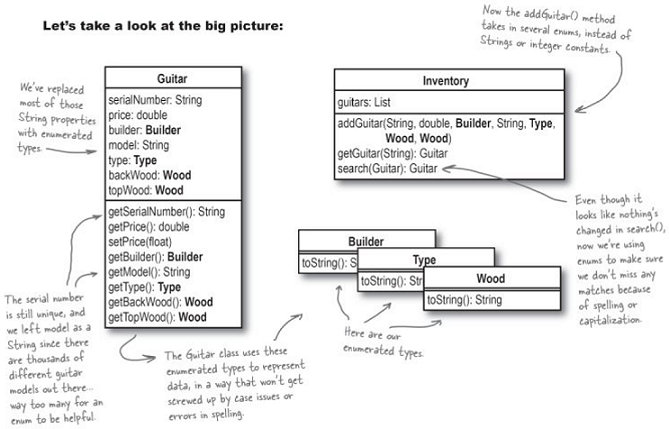
重新設計之後,成功了加入對 Mandolin 的支援,以下是完整的設計圖






如果安裝 Ubnutu 僅安裝 console mode 時,在敲鍵盤就會不時有討厭的嗶聲出現
在 GUI 裡面還可以在系統裡面關閉,但僅有 console 要怎麼關呢??
若要暫時先關閉,可以輸入以下指令:
shell> sudo rmmod pcspkr
如果要一勞永逸,就編輯「/etc/modprobe.d/blacklist」,並加入以下這一行:
blacklist pcspkr
這樣就可以永遠跟討厭的嗶嗶嗶說 goodbye 啦!
參考資料
何謂交易? 這一篇文章寫得不錯,可以參考一下…
在 Oracle 中,控制交易的敘述有三個,分別為:
COMMIT
保存對資料的所有更動,清除交易中所有的 savepoint,並釋放對交易的鎖定。
ROLLBACK
復原目前交易中已經完成的工作,也就是最後一次的 COMMIT 之後所有的對資料的變更都會被回復。
SAVEPOINT
可以讓使用者自訂復原的點,這可以讓 ROLLBACK 不會一次全作,而是只復原到特定的點。
關於 COMMIT 與 ROLLBACK 的使用,其實就是加在要 COMMIT 或是 ROLLBACK 的地方就可以了!
比較特殊的是 SAVEPOINT,以下簡單介紹 SAVEPOINT 的用法。
首先先搜尋 counties 中的資料:

接著執行以下 SQL 指令:

由結果可以很明顯看到,在 SAVEPOINT Belgium 之後被更改的資料都被還原囉!
連線至資料庫
一開始 Oracle 安裝完成後,除了系統管理員(SYS、SYSTEM、SYSMAN) 之外,其他帳號都是被鎖住的,因此若是要使用其他帳號登入的話,必須先將帳號解除鎖定,以下示範將帳號「hr」解除鎖定:
在 Oracle 中,schema 的名稱跟 user 名稱是相同的
除了這個跟 SQL Server 與 MySQL 不太一樣,Oracle 也只有一個 database,而分類的方式就是利用 schema 的方式進行分類,然後再用與 schema 名稱相同的使用者名稱進行資料庫的連線。
SID 即為 Oracle database 名稱
在連線資料庫的時候,必須指定 SID,而 SID 指的就是 Oracle database 的名稱;而由於每個 Oracle 只有一個 database,因此 SID 在 Oracle 安裝時就會設定好,並且要記好。
Select + Regular Expression
範例一:搜尋 job_id 的值中包含 man 或是 mgr 且大小寫不拘的員工

詳細使用方式可以參考官方網站說明。
範例二:搜尋 last_name 的值中包含兩個母音字母(a、e、i、o、u)且大小且不拘的員工

其中「\1」代表第一個 pattern,也就是「([aeiou])」。(每個 pattern 都會由小括號包起來)
詳細使用方式可以參考官方網站說明。
範例三:將搜尋結果的電話格式由「nnn.nnn.nnnn」改為「(nnn) nnn-nnnn」

詳細使用方式可以參考官方網站說明。
範例四:搜尋地址的街道號碼(格式可能為「1234」、「123-34」或是「12-34-56」)

其中 regexp_substr() 中的後兩個參數為 1,分別代表「從第一個字元開始搜尋」以及「符合搜尋條件幾次」,詳細使用方式可以參考官方網站說明。
範例五:判斷地址中有幾個空白字元

詳細使用方式可以參考官方網站說明。
範例六:取得地址中諦一個空白所出現的位置索引

其中 regexp_instr() 中的後兩個參數為 1,分別代表「從第一個字元開始搜尋」以及「符合搜尋條件幾次」,詳細使用方式可以參考官方網站說明。
Built-in & Aggregate Function
範例一:搜尋員工在職時間

範例二:列出員工年資

範例三:列出目前系統時間

PS. 搜尋 DUAL table 會被罵 dummy 喔! Orz
範例四: 字串格式化 01 (原本格式範例:「01-7月 -98」)

範例五:字串格式化 02 (原本格式範例:「01-7月 -98」) 
範例六:字串格式化 03 (原本格式範例:「2600」)

範例七:將字串轉為數字並進行運算

範例八:同時使用多個 aggregation function

許多 function 都已經內建於 Oracle 中,例如:ROUND、TRUNC、LOWER、UPPER、INITCAP、LTRIM….等等,都可以直接拿來使用。
當然這些 function 的數量很多,很難一一介紹,如果想知道 Oracle 提供了哪些 function 以及要如何使用,可以參考官方網站的文件。
範例九:在 job_id 有 CLERK 字眼的群組中,取得 salary 為 3000 的排名以及多少百分比
![]()
範例十:查詢員工與獎金相關資料(使用 NVL 與 NVL2)

範例十一:使用 CASE 函數進行年資調整 
CASE 的詳細使用方式可以參考官方網站說明。
範例十二:使用 DECODE 函數進行資料比對與條件判斷

DECODE 的詳細使用方式可以參考官方網站說明。
若要進一步瞭解 Oracle 提供的 Aggregation Function 有哪些,以及詳細的使用方式,可以參考官方網站的文件說明;而 Expression 的部份,可以參考此處。
管理介面
Enterprise Manager
當 Oracle 11g 安裝完成後,可以透過 Web Enterprise Manager 進行管理,但有一點必須注意! 就是不同台電腦安裝 Oracle 可能會有不同的 port number !
基本上連線資訊會在安裝完成後顯示在安裝完成的畫面上,如果可以當然是要記下來囉! 如果真的忘記了,還是有幾種方式可以查到:
從 server 端,選「開始 → 所有程式 → Oracle - OraDb11g_home1 → Database Control - orcl」進入 Web Enterprise Manager。
使用記事本開啟「C:\Oracle\product\11.1.0\db_1\install\portlist.ini」檔,內容可能像下面這樣:
Ultra Search HTTP 連接埠號碼 =5620
Enterprise Manager 主控台 HTTP 連接埠 (orcl) = 5500
Enterprise Manager 代理程式連接埠 (orcl) = 3938
這個管理介面在 11g 版本中已經不存在囉!
參考資料
Oracle 與其他 RDBMS 不同之處
Schema
在 Oracle 中,Schema 與特定的 user 連結,因此通常也直接以該 user 的名稱來命名,但其中包含的是許多資料庫相關物件的集合,包含 table、index、data …. 等等。
以下是官方的英文解釋:
參考資料A schema is a collection of database objects.
A schema is owned by a database user and has the same name
as that user.
Schema objects are logical structures created by users to contain, or reference, their data.
Schema objects include structures like tables, views, and indexes.
You can create and manipulate schema objects using Oracle Enterprise Manager.
SID 就是資料庫名稱(database name),別想太多了!
以下是英文解釋:
The Oracle System ID (SID) is used to uniquely identify a particular database on a system. For this reason, one cannot have
more than one database with the same SID on a computer system.
若是要使用特定使用者帳號,要確定該使用者帳號沒有被鎖定(Lock,在 Oracle 安裝時只有 SYS、SYSTEM、SYSMAN、DBSNMP 四個帳號開放),基本上要有管理者(SYS、SYSTEM、SYSMAN)權限才能開放。
在 SQL Plus 中可以直接變換為管理者連線:
SQL> conn sys as sysdba;
輸入密碼; #此處輸入 sys 的密碼
已連線.
接著就可以將特定的使用者帳號解除鎖定:
#將帳號 SCOTT 解除鎖定
SQL> alter user scott identified by passwordofscott account unlock;
參考資訊
在 SQL Plus 中輸入以下指令即可查詢:
SQL> select * from v$tablespace;
參考資料
資料庫物件(Database Object)
在 Oracle 中有許多不同的物件,以下列出說明:
Tables
這很常見了,應該不太需要說明了吧!
Views
這很常見了,應該不太需要說明了吧!
Indexes
這很常見了,應該不太需要說明了吧!
Functions
以 PL/SQL 所開發的程式,存於資料庫中,有回傳值。
Procedures
以 PL/SQL 所開發的程式,存於資料庫中,沒有回傳值。
Packages
包含可以在資料庫中儲存與執行的 function 與 procedure。
Triggers
這很常見了,應該不太需要說明了吧!
Types
自訂的資料型態,而這種自訂型態可以指定為 table 中某個 column 的型態;亦即在 Oracle 中,資料型態是可以自訂的,但自訂的型態有效範圍僅限於 schema 中。
Sequences
用來產生唯一的整數值之用;可以透過 sequence 來產生 primary key 的值喔!
何謂 connection pool ?
就是為了要節省開啟、關閉資料庫連線時所造成大量的資源與時間耗損所設計出來的機制。
如何達成以上目的的呢 ?
以下直接引用 MSDN2 的解釋來說明:
Connection pooling reduces the number of times that new connections must be opened. The pooler maintains ownership of the physical connection. It manages connections by keeping alive a set of active connections for each given connection configuration. Whenever a user calls Open on a connection, the pooler looks for an available connection in the pool. If a pooled connection is available, it returns it to the caller instead of opening a new connection. When the application calls Close on the connection, the pooler returns it to the pooled set of active connections instead of closing it. Once the connection is returned to the pool, it is ready to be reused on the next Open call.
從上面可以瞭解,一旦當 connection string 被指定後,ADO.NET 會自動產生多個 active connection 並置於 connection pool 中。
一旦程式中有 connection open() 的動作,就直接從 pool 中拉出一個 active connection 並回傳;若程式中有 connection close() 或是 Dispose() 的動作,則是直接將 connection 歸還給 pool,不會實際將 connection 關閉。
【注意】前提是這些 connection 的 connection string 是一致的,才會使用到同一個 connection pool 所提供的 connection。
Connection Pool 之間是如何區別的呢 ?
以下直接引用 MSDN2 的解釋來說明:
Connections are pooled per process, per application domain, per connection string and when integrated security is used, per Windows identity.
可以知道,connection pool 可以同時不只有一個(若是同時利用兩個不同的 connection string 產生 connection),可以同時有多個存在;而不同 process、不同的 application domain、不同的 connection string、甚至不同的 Windows identity 都會產生不同的 connection pool 來維護各自的資料庫連線。
要如何才能使用 Connection Pool 的功能呢 ?
以下直接引用 MSDN2 的解釋來說明:
Pooling connections can significantly enhance the performance and scalability of your application. By default, connection pooling is enabled in ADO.NET. Unless you explicitly disable it, the pooler optimizes the connections as they are opened and closed in your application. You can also supply several connection string modifiers to control connection pooling behavior.
恩…微軟直接在 ADO.NET 預設開啟 Connection Pooling 的機制了,想要關閉或是進行調整的話,可以在 connection string 中指定。只要指定好 connection string,開始連線時,ADO.NET 就會自動建立 connection pool 供程式使用了!
Connection Pool 中的連線預設都不關閉嗎 ?
以下直接引用 MSDN2 的解釋來說明:
If MinPoolSize is either not specified in the connection string or is specified as zero, the connections in the pool will be closed after a period of inactivity. However, if the specified MinPoolSize is greater than zero, the connection pool is not destroyed until the AppDomain is unloaded and the process ends.
因此可以知道,在 connection string 中的「MinPoolSize」屬性設定,會影響到資料庫連線在 connection pool 中是否會自動關閉。
Connection Pooling 細節的運作機制
以下直接引用 MSDN2 的解釋來說明:
The connection pooler satisfies requests for connections by reallocating connections as they are released back into the pool. If the maximum pool size has been reached and no usable connection is available, the request is queued. The pooler then tries to reclaim any connections until the time-out is reached (the default is 15 seconds). If the pooler cannot satisfy the request before the connection times out, an exception is thrown.
很清楚的,可以知道 ADO.NET connection pooling 的運作機制如下:
何謂 Pool Fragmentation ?
常發生在 web application 中,原因是因為在 process 運作的期間產生了太多個 connection pool,因此 web server 必須維護大量的 connection,造成資源的虛耗,此種現象稱為「Pool Fragmentation」。
為何會發生 Pool Fragmentation ?
發生 Pool Fragmentation 可能會有兩種原因:
使用 Windows Authentication 的方式進行使用者認證
有些 web application 會採用 Windows Authentication 的方式認證使用者,而先前提過,使用不同的 windows identity 進行資料庫連線要求時,會產生不同的 connection pool,而當 connection pool 產生時,會預設產生出數個 connection 以供未來資料庫連線要求之用。
因此若要解決這個問題,可以將使用者認證的資訊存於資料庫中,進行認證時,只要統一經由相同的連線向相同的存取認證資訊即可。
同時連結多個資料庫
連結多個資料庫表示 connection string 會不同,當 connection string 不同時,相對的也會產生出不同的 connection pool。
而要解決這個問題,可以透過 SQL 語法中的「USE」關鍵字,直接在同一個連線中轉移資料庫並進行相關資料的擷取。
實作相關資訊
替代路徑是包含在使用案例裡的一或多個步驟,是選擇性的(optional)或提供替代性的(alternate)方式通過使用案例。
替代路徑可能是增加到主要路徑裡的額外步驟,或是提供步驟,讓你以完全不同於主要路徑的方式,到達使用案例的目標。
你可以有多條替代路徑提供額外的步驟,以及多重條件從起始條件(start condition)通往終止條件(stop condition)。
甚至可以有替代路徑早一點終止使用案例。
最近使用 Google Docs 將文章發佈至 Blogger,但是都發現格式跑掉很多
之前都沒有這種情形.......
所以決定找個好用的工具來處理這個問題,於是就找到了 Zoundry Raven 這一套軟體
看了許多介紹,是蠻多人推薦的離線編輯軟體
有這個需求的人或許可是試試看這一套囉!
<!-- syntax highlighting -->
<link href="http://godleon.googlepages.com/SyntaxHighlighter.css" rel="stylesheet" type="text/css" />
<script src="http://godleon.googlepages.com/shCore.js" type="text/javascript" xml:space="preserve"/>
<script src="http://godleon.googlepages.com/shBrushJava.js" type="text/javascript" xml:space="preserve" />
<script src="http://godleon.googlepages.com/shBrushCss.js" type="text/javascript" xml:space="preserve" />
<script src="http://godleon.googlepages.com/shBrushXml.js" type="text/javascript" xml:space="preserve" />
<script src="http://godleon.googlepages.com/shBrushVb.js" type="text/javascript" xml:space="preserve" />
<script src="http://godleon.googlepages.com/shBrushSql.js" type="text/javascript" xml:space="preserve" />
<script src="http://godleon.googlepages.com/shBrushRuby.js" type="text/javascript" xml:space="preserve" />
<script src="http://godleon.googlepages.com/shBrushPython.js" type="text/javascript" xml:space="preserve" />
<script src="http://godleon.googlepages.com/shBrushPhp.js" type="text/javascript" xml:space="preserve" />
<script src="http://godleon.googlepages.com/shBrushJScript.js" type="text/javascript" xml:space="preserve" />
<script src="http://godleon.googlepages.com/shBrushDelphi.js" type="text/javascript" xml:space="preserve" />
<script src="http://godleon.googlepages.com/shBrushCSharp.js" type="text/javascript" xml:space="preserve" />
<script src="http://godleon.googlepages.com/shBrushCpp.js" type="text/javascript" xml:space="preserve" />
<script type="text/javascript" xml:space="preserve">
dp.SyntaxHighlighter.ClipboardSwf = 'http://godleon.googlepages.com/clipboard.swf';
dp.SyntaxHighlighter.BloggerMode();
dp.SyntaxHighlighter.HighlightAll('code');
</script>
dp.SyntaxHighlighter.BloggerMode();
dp.SyntaxHighlighter.HighlightAll('code');
<!-- end of syntax highlighting -->




