提到網路,OSI 七層架構是一定要說明一下的;雖然目前大家所使用的 TCP/IP 並沒有完全遵循 OSI 七層架構去實作,不過其定義了一個網路架構的典範,因此還是必須去瞭解架構中每一層間的關係。
以下分別就 OSI 七層中,每一層所負責的工作進行介紹:
- Physical Layer (實體層)
負責傳送電子訊號,讓兩台透過網路線連接的電腦可以互相傳遞電子訊號。基本上此層不太需要去深入瞭解,因為這是硬體(NIC)所負責的工作。
- Data Link Layer (資料鏈結層)
此層的工作是確保資料傳輸的可靠性,提供更上層資料品質的保證。目前有 HDLC、SDLC....等協定屬於此層。
- Network Layer (網路層)
前面提到的兩層是用來負責實體相連機器間的資料傳輸,而 Network Layer 則是負責「網路上」兩部機器之間的傳輸,因此這一層有 routing(擇徑)、addressing(定址)、error handling(錯誤處理)....等功能。
屬於此層較常用的協定有:
- IP (Internet Protocol)
負責在不同網路主機間,傳輸資料的協定。 - ICMP (Internet Control Message Protocol)
定義資料在網路上傳輸時若發生問題,錯誤訊息的格式與回報方式。
- IP (Internet Protocol)
- Transport Layer (傳輸層)
雖然 Network Layer 會負責將資料傳送到遠方的機器,但是卻無法保證資料可以完整無誤的傳送完成(例如:中間的封包沒有傳送至目的地),因此 Transport Layer 就有提供 error recovery 的功能,讓資料傳輸更為可靠。目前有 TCP、X.25....等協定皆屬於此層。
屬於此層較常用的協定有:
- TCP (Transport Control Protocol)
負責讓資料在網路上的不同主機間進行可靠的傳輸,屬於 connection 的通訊協定。
- UDP (User Datagram Protocol)
負責讓資料在網路上的不同主機間進行快速的傳輸(但不可靠),屬於 connectionless 的通訊協定。
- TCP (Transport Control Protocol)
- Session Layer (交談層)
此層負責處理傳送雙方間交談處理與協調,並管理資料的交換,主要的目的在於管控資料何時該傳送、何時該接收、或是傳送接收同時進行。 - Presentation Layer (展示層)
先前幾層的目的,是將資料完整無誤的傳至對方主機,但所有資料皆是由 0 與 1 所組成,對方完全不知道資料所代表的意義為何,而 Presentation Layer 的目的就是負責將資料轉換為對方主機瞭解的格式,因此所涉及的工作大概就是字碼轉換、資料轉換、資料壓縮解壓縮....等等。 - Application Layer (應用層)
此層所負責的工作是提供作業系統中的應用程式使用網路進行資料的傳輸,包括連線的建立、中止,網路管理的方式....等等。目前有 HTTP、FTP、POP3.....等協定皆屬於此層。
屬於此層較常用的協定有:
- Telnet
遠端登入協定,可用來登入網路上任何一台主機。 - FTP (File Transfer Protocol)
用來讓網路上的兩台主機間,進行檔案傳輸的協定。 - TFTP (Trivial File Transfer Protocol)
與 FTP 相同功能,但使用的是 UDP 而非 TCP。 - SMTP (Simple Mail Transfer Protocol)
將電子郵件傳送至網路上任何一部主機的通訊協定。 - SNMP (Simple Network Management Protocol)
可用來透過網路進行主機監控的通訊協定。 - DNS (Domain Name Server)
負責將主機名稱轉換為相對應的 IP address。
- Telnet
每一層的關係是密不可分的,每一層都是上一層的基礎,唯有每一層的工作都成功完成,才可以透過 Application Layer 將資料成功的由網路傳遞至對方主機。
TCP/IP 4 Layers
剛學網路,OSI 7 Layers 是肯定不能不知道的,而由於 OSI 七層實在是太多,所以為了實作的方便上,TCP/IP 中改為四層,如下圖所示:(詳細資訊可參考 RFC 1122 與 RFC 1123)

- Link Layer
亦稱為「Data Link Layer」,負責處理與硬體相關的部分,舉凡網路裝置在 OS 中的驅動程式、接在網路裝置上的線材....等等,都屬於此層的範圍。
代表:MAC(因此與 MAC 相關的協定 ARP 與 RARP 也屬於此層)。
- Network Layer
亦稱為「Internet Layer」,負責封包於網路上的移動、routing....等工作。
代表:IP(Internet Protocol)、ICMP(Internet Control Message Protocol)、IGMP(Internet Group Management Protocol)。
- Transport Layer
負責建立主機兩端之間的資料流,藉以傳遞資料。
代表:TCP(Transmission Control Protocol)、UDP(User Datagram Protocol)。
TCP:為可靠的資料傳輸,因此下一層的 Application 不需考慮資料是否正確完整傳遞。
UDP:不可靠的資料傳輸,因此若需要考慮資料是否有正確完整傳輸,必須實作於 Application Layer。
- Application Layer
處理應用程式的相關係節,一般常見到的應用程式有 Telnet、FTP、SMTP、SNMP....等等。
基本上每層的運作是各司其職,只要對於自己的上下兩層提供介面,可以接收來自下層的訊息,進行正確處理後,再正確的往上傳遞即可。因此假設使用者使用的是 FTP 或是 SMTP 服務,對於 Link Layer 來說,也只是負責傳送不同的 01 組合的電子訊號而已。
由於 Internet 的發展已經有一段歷史了,從原本的小型網路,逐漸的擴大變成現在的全球網路,而用來連接不同 network 的設備,稱為 router;此外,當然還會有很多廠商做出不同的硬體來連上 Internet,其中比較常見的架構有 Ethernet、Token Ring、PPP、FDDI....等等。而這些硬體若是支援 TCP/IP,基本上是可以沒有問題的相互連結並傳遞資料,而這是如何做到呢? 其實就是使用 router 所連接起來的,以下用一張圖來解釋:
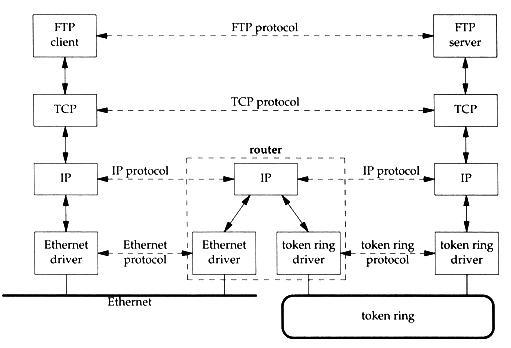
router 擁有多個實體介面,支援多種不同的網路架構,當然也認識不同網路架構所產生的封包格式;而 router 除了認得許多不同的封包格式外,還提供了 routing 的功能,可將資料在不同的 network 之間傳遞,而傳遞的依據正是 IP header 中所包含的資訊。
【備註】router 屬於 Network Layer 的硬體
然而在 TCP/IP 的架構中,資料從 Application Layer 傳遞下來後,在 Network Layer 中會加入 IP header,在裡面放置對方的資訊,router 接收到後,就可以知道此封包應該透過那個介面傳遞出去了!
當然,還會將封包的格式進行「Ehternet -> Token Ring」或是「Token Ring -> Ethernet」的轉換! 到了對方網路中,OS 中的 driver 才可以正確辨識。
另外,還有一個值得一提的硬體設備,稱為「bridge」,負責連接相同網路架構的小型 LAN,進而成為一個單一個 LAN,屬於 Link Layer,因此無法連接不同的網路硬體架構。
TCP/IP Layering
TCP/IP 協定中並非只有 TCP 與 IP 兩個協定,而是由許多不同協定結合而成 TCP/IP protocol suit,只是 TCP 與 IP 是其中兩個較為重要的協定,以下用一張圖來表示各協定的分層:
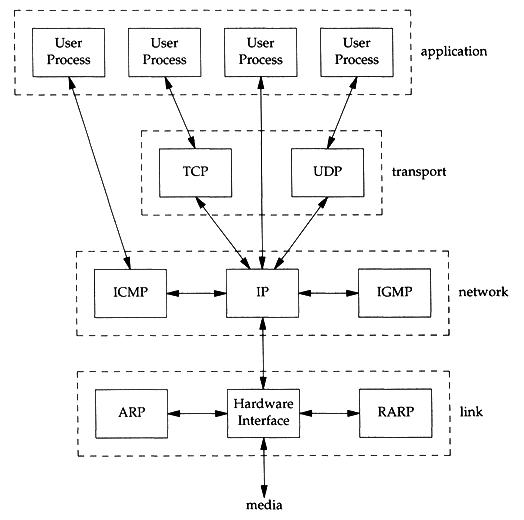
- TCP
屬於 Transport Layer,提供可靠的傳輸,因此即使在 Network Layer 中的 IP 屬於不可靠的傳輸也無所謂,因為上層已經加上確認的功能。而 base 在 TCP 協定上的應用也很多,例如:Telnet、FTP、SMTP....等等。
- UDP
用來傳送與接收應用程式所發的 datagram,由於傳送後並沒有機制可以確認對方是否收到,因此屬於不可靠傳輸;雖然如此,還是有許多應用,例如:SNMP、VPN....等等。 - IP
為 Network Layer 中最重要的協定,作用是進行網路的繞徑(routing),因此為了讓應用程式的資料可以在網路上正確傳送,TCP 與 UDP 都不可避免的會使用到 IP。 - ICMP
可說是 IP 的附屬協定,作用是 packet 透過 IP 進行 routing 時,用來與對方主機或傳送路經上的 router 交換一些重要或是錯誤的訊息。一般來說,ICMP 大多是給 IP 所使用,但也有可能被更上層的應用程式所使用,例如:ping、traceroute....等程式。 - IGMP(Internet Group management Protocol)
此協定會送出 UDP datagram 給網路上的多台主機(注意! 並非所有主機! 跟 broadcast 不同),稱為 multicasting。 - ARP(Address Resolution Protocol) 與 RARP(Reverse Address Resolution Protocol)
用來處理 NIC MAC address 與實體 IP address 的對應,也是提供給 IP 所使用。
網路位址
每一個主機要連上網際網路,都必須要有一個 public IP address,而 IP address 長度為 32 bit,以每 8 bit 為一區間,再將其轉換為數字,會變成類似以下的內容:
140.137.1.5
140.137.20.100
.......等等
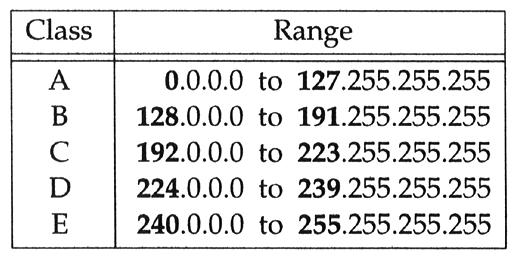
而 InterNIC 為了管理方便,將所有的 IP address(32 bit 一共會有 2^32 個 IP address 可用) 分為五個等級,每個等級的子網路切割的方式都不相同,詳細的說明可以參考此篇文章(StudyArea->學習網路->TCP/IP基礎->IP位址)中 Net Mask 的部分。
以下僅用一張圖來說明五個等級的網段,IP address 分配的情形:
Encapsulation
當應用程式要透過網路傳送資料時,資料必須經由 Application Layer 往下層傳送,最後到 Link Layer 後再透過網路卡出去,中間針對資料進行了許多的加工(最後加工後的資料大小會介於 46~1500 bytes 之間),才可以讓資料正確無誤的傳送至對方主機上,以下用一張圖來說明:
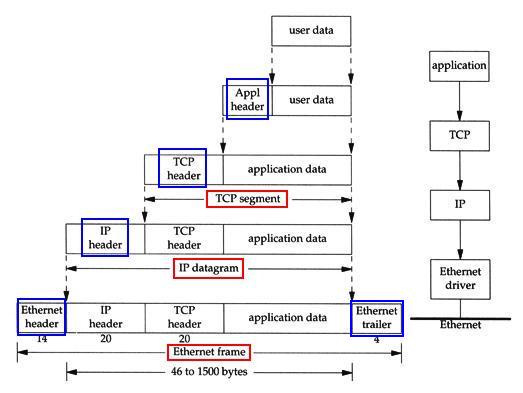
- Application(Application Layer) -> TCP(Transport Layer)
加入了 Applcation header 到原本的資料前方,此時稱為 Application data。
- TCP(Transport Layer) -> IP(Network Layer)
再加入 TCP header(20 bytes) 到資料前方,稱為 TCP segment。
- IP(Network Layer) -> Ethernet driver(Link Layer)
再加入 IP header(20 bytes) 到資料前方,此時稱為 IP datagram(packet)。
- Ethernet driver(Link Layer) -> Ethernet
最後再加入 Ethernet header 以及 Ethernet tailer 到資料的頭尾,此時稱為 Ethernet frame。
接著,有一個很重要的觀念,即是「要如何判斷資料是屬於那個應用程式? 或是那個協定呢?」,這邊從最上層往下開始講起:
- Application(Application Layer) -> TCP(Transport Layer)
在 Transport Layer 中,TCP 或是 UDP,為了辨識來自上一層的資料是屬於何種應用程式,在TCP header(或 UDP header) 中,有兩個個長度為 16 bit,名稱為「source port number」以及「destination port number」的欄位,是用來紀錄兩端主機的應用程式所使用的 port number,以下列出幾個應用程式:(若想瞭解更多應用程式所使用的 port number,可參考 RFC 1340)
應用程式
Protocol
port number
FTP
TCP
21
SSH
TCP
22
SMTP
TCP
25
DNS
TCP
53
UDP
53
HTTP
TCP
80
- TCP(Transport Layer) -> IP(Network Layer)
在 Network Layer 中,最重要的就是 IP 協定了! 有許多協定(TCP、UDP、ICMP、IGMP)都必須將資料交給 IP 來處理,然而 IP 要怎麼判斷這些協定為何,或是屬於一層呢? 其實作法很簡單,只要在 IP header 中加入辨識各協定的資訊即可,因此在 IP header 中有一個長度為 8 bit,名稱為「protocol」的欄位來儲存用來判斷這些協定的資訊,而對照表如下:
====== 以下是備註 ======協定
decimal
binary
ICMP
1
00000001
IGMP
2
00000010
TCP
6
00000110
UDP
17
00010001
看到這邊,可能有人會認為,為什麼在 Network Layer 中的 protocol 欄位,所加入的協定辨識資訊會有 ICMP 跟 IGMP 呢? 不是應該只有 TCP 與 UDP 嗎? 因為 IP 與 ICMP、IGMP 都屬於同一層阿....
原因是在上述這四個通訊協定都會傳送資料給 IP(各協定遞送資料的關係可以參考上一個部分的圖來瞭解協定之間資料傳遞的關係),因此在 IP header 中的 protocol 欄位必須要將這些協定作區隔。 - IP(Network Layer) -> Ethernet driver(Link Layer)
當然在 Link Layer 中,也要能夠判斷來自上一層的資料是屬於什麼協定(IP or ARP or RARP),因此同樣在 Ethernet header 中也有一個長度 16 bit 的欄位,名稱為「frame type」的欄位,用來儲存辨識來自上層(不一定是上層)協定的資料。
====== 以下是備註 ======
同樣的,IP 與 ARP、RARP 也屬於不同的 Layer,也是因為這三個協定都會直接傳送資料給 Ethernet driver,因此在 Ethernet header 中的 frame type 欄位必須要儲存這些協定的辨識資訊。
看到這邊,大概也有些眉目了,資料的 Encapsulation 是會根據所使用的協定,一層一層的由上而下,將特定的辨識資訊加入至 header 中,只要參考上一個部分的圖,就可以清楚瞭解各協定間資料傳遞的情形,觀念自然會清晰不混淆。
Demultiplexing
上一段介紹從上層到下層的過程中,下層會根據來至上層的資料,在 header 中加入辨識資訊以供辨識,那到了對方主機後,自然資料會從 Link Layer(or Network Layer) 開始拆解 header 一訓,一層一層往上,最後到 Application Layer 由應用程式接收並處理,而這個過程,就稱為「Demultiplexing」。
以下用一張圖來進行說明:
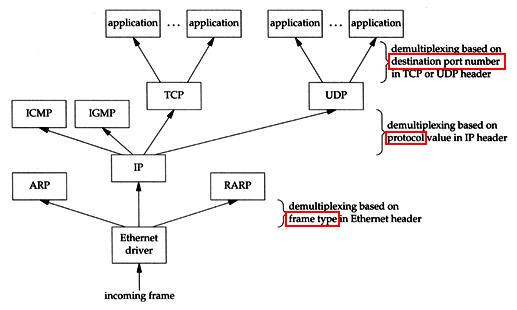
- Ethernet header
當 NIC 接收到來自對方主機的 Ethernet frame 之後,會根據 Ethernet header 中的 frame type 欄位,判斷資料是要傳給那個協定,可能是 IP(Network Layer),或是 ARP、RARP(Link Layer)。
- IP header
當資料拆掉 Ethernet header 後傳送給 IP,此時 IP 就可以根據 IP header 中的 protocol 欄位,判斷資料要傳送的協定是 ICMP、IGMP(Network Layer) 或是 TCP、UDP(Transport Layer)。
- TCP(or UDP) header
而在 TCP(or UDP) header 中,就可以根據 destination port number 欄位,來判斷這個資料是要交給那個應用程式去處理了。